import pandas as pd
import numpy as np
import dask.dataframe as dd
# Timers
from dask.diagnostics import ProgressBar
from tqdm import tqdm
import time
# I/O Utilities
import requests
from bs4 import BeautifulSoup
import re
import os
from datetime import datetime
import gc
# Display
import matplotlib.pyplot as pltThe following example involves a situation where I want to analyze historical data on Bay Area Rapid Transit (BART) ridership at the station/hour level. BART kindly makes such ridership information publicly available on their open data portal. This post will examine the following workflow:
- Use
bs4andrequeststo reverse engineer an API for the data and batch download it. - Use the apache parquet to efficiently store the data locally.
- Use
daskfor efficient read-in of the data.
This walkthrough largely serves to highlight the efficiency and the ease of use of dask and parquet. I find that:
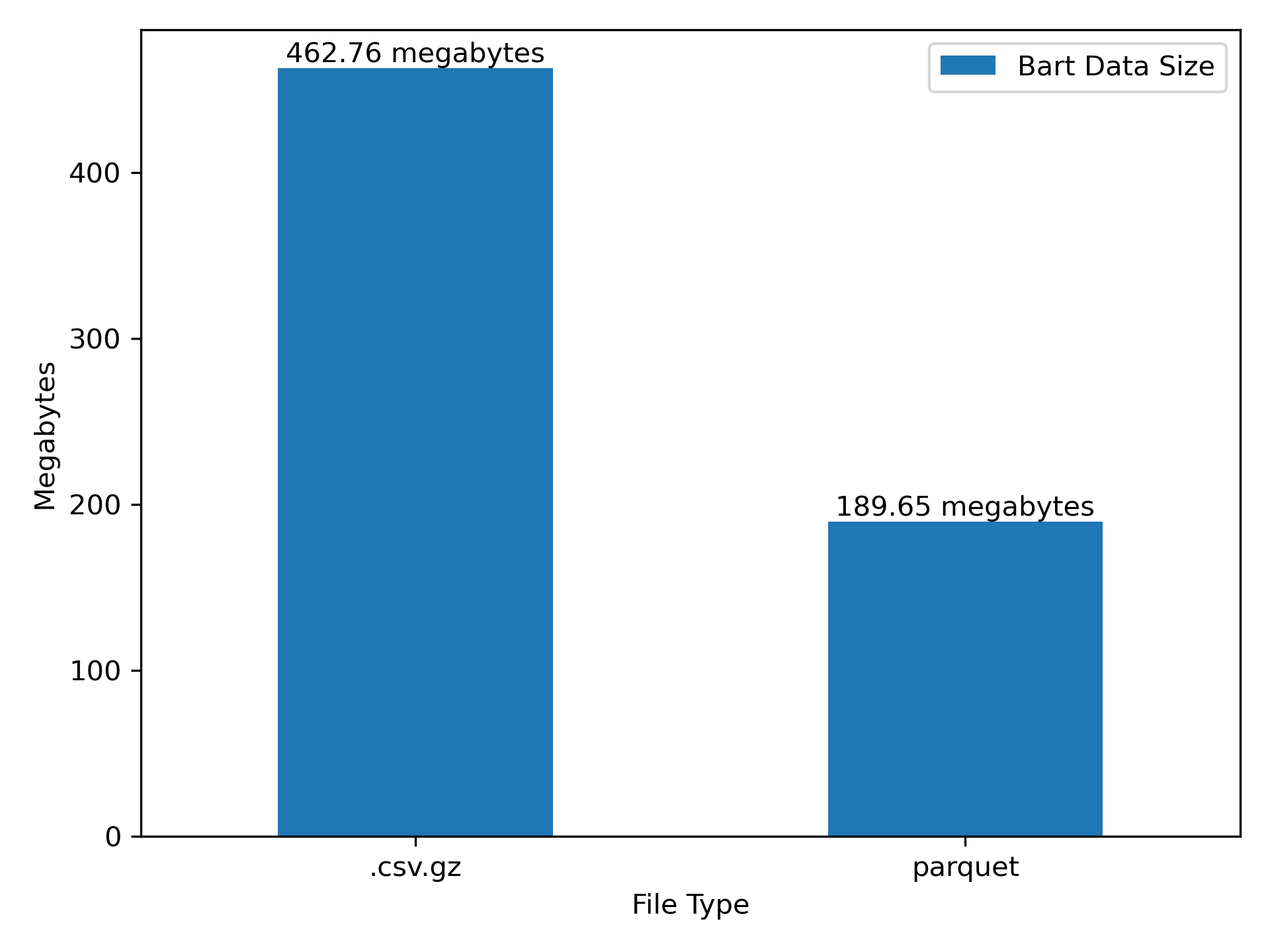
1.) Parquet is a relatively efficient format for storage (Figure 3)
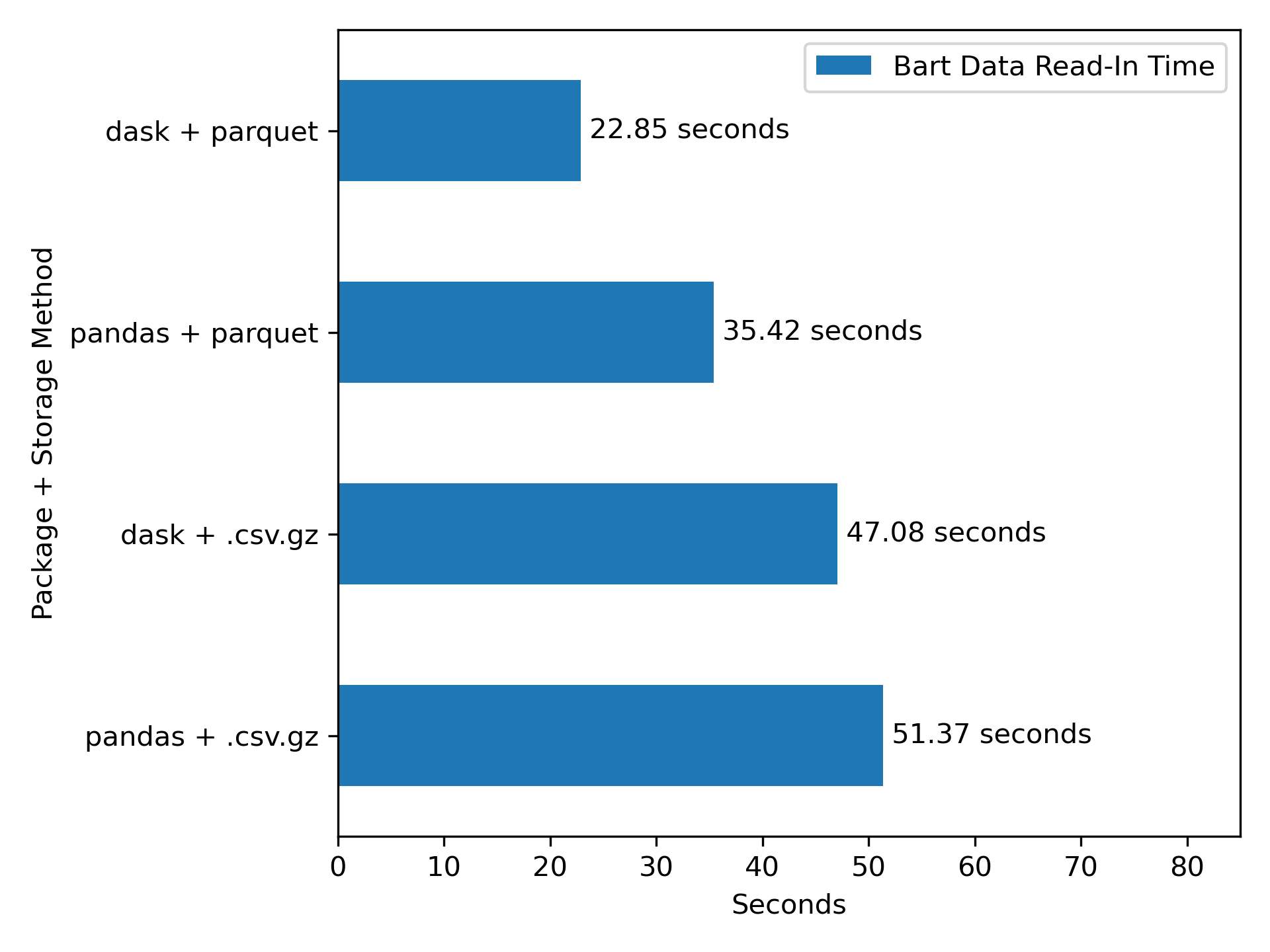
2.) dask+parquet is a relatively fast for data IO (Figure 4)
I should note that my adoption of dask and parquet storage is due to the influence of two of my day-job coworkers, Batool Hasan and Konrad Franco, after we leveraged them for an internal project with a similar workflow.
As an aside, I highly recommend watching the “Background” section of this talk for some basic information on dask and how it differs from Spark, DuckDB, and polars. The talk also features some comprehensive benchmarks of dask and establishes the core differences between [dask and Spark] in one group, and [polars and DuckDB] in the other.
Scraping our data
Anyways, to start, here is the homepage of the BART data portal:
I’ll set up a scraping script using requests and BeautifulSoup to build access to the BART hourly ridership data.
# URL of the webpage to scrape
url = 'https://afcweb.bart.gov/ridership/origin-destination/'
url'https://afcweb.bart.gov/ridership/origin-destination/'# Send an HTTP GET request to the webpage
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
# Parse the content of the webpage with Beautiful Soup
soup = BeautifulSoup(response.text, 'html.parser')
else:
print("Failed to retrieve the webpage")The page is laid out as follows:

My target here is the set of .csv.gz (compressed .csv files) that contain hourly ridership totals between each station pairing. These are all links, thus are in <a> </a> tags, and have an href that ends in .csv.gz. The following captures links to that specification:
links = soup.find_all(
# final all <a></a> content
'a',
# filter to only those links with href ending in .csv.gz
href=lambda x: x and x.endswith(".csv.gz")
)
# example output
links[0]<a href="date-hour-soo-dest-2018.csv.gz"> date-hour-soo-dest-2018.csv.gz</a>I’m specifically interested in the file that this piece of html links to, which is contained in the href tag. I can capture the href for each of these pieces of html as follows
files = [l.get('href') for l in links]
# example output
files[0]'date-hour-soo-dest-2018.csv.gz'I’ve now captured the filename, which is a relative url. To download this, I’ll need to convert this to a full url, by concatenating the base url to each of the files’ relative urls. This leaves us with direct links that each prompt the download of one year’s worth of hourly trip totals between the station pairings in the system:
file_urls = [url + f for f in files]
file_urls['https://afcweb.bart.gov/ridership/origin-destination/date-hour-soo-dest-2018.csv.gz',
'https://afcweb.bart.gov/ridership/origin-destination/date-hour-soo-dest-2019.csv.gz',
'https://afcweb.bart.gov/ridership/origin-destination/date-hour-soo-dest-2020.csv.gz',
'https://afcweb.bart.gov/ridership/origin-destination/date-hour-soo-dest-2021.csv.gz',
'https://afcweb.bart.gov/ridership/origin-destination/date-hour-soo-dest-2022.csv.gz',
'https://afcweb.bart.gov/ridership/origin-destination/date-hour-soo-dest-2023.csv.gz',
'https://afcweb.bart.gov/ridership/origin-destination/date-hour-soo-dest-2024.csv.gz']This is our target data, so before proceeding to download all of it for local storage, we’ll profile the sizes of each file and the total download:
counter = 1
total = 0
for f in file_urls:
response = requests.head(f)
# Retrieve the file size for each file
file_size = int(response.headers.get('Content-Length', 0))
# Keep track of the total file size
total += file_size
print(f"File {counter} size: {file_size} bytes ({round(file_size*10e-7, 2)} mega-bytes)")
counter += 1
print(f"Total size of data: {total*10e-7} mega-bytes")File 1 size: 38627139 bytes (38.63 mega-bytes)
File 2 size: 38177159 bytes (38.18 mega-bytes)
File 3 size: 21415653 bytes (21.42 mega-bytes)
File 4 size: 24350926 bytes (24.35 mega-bytes)
File 5 size: 30546036 bytes (30.55 mega-bytes)
File 6 size: 32224174 bytes (32.22 mega-bytes)
File 7 size: 16468035 bytes (16.47 mega-bytes)
Total size of data: 201.809122 mega-bytesWe’ll proceed to download all of this into a folder, data. Here I take advantage of tqdm’s progress bar so that I can track the potentially large job’s progress. I also add logic for two conditions:
- make sure that the ingest doesn’t re-read files that I already store locally.
- UNLESS, it the data is from the current year, in which case it likely contains more data than the present file for that year.
current_year: str = str(datetime.today().year)
# Create the "data" folder if it doesn't exist
if not os.path.exists('data'):
os.makedirs('data')
# Download and save the files
for url in tqdm(file_urls):
filename: str = os.path.join('data', os.path.basename(url))
current_year_data: bool = re.search("\d{4}", url)[0] == current_year
file_exists: bool = os.path.exists(filename)
if file_exists and not current_year_data:
pass
else:
response = requests.get(url)
if response.status_code == 200:
with open(filename, 'wb') as file:
file.write(response.content)
else:
print(f"Failed to download: {url}")100%|██████████| 7/7 [00:00<00:00, 7.79it/s]Since we are storing a large amount of data in the project directory, we will also set up a .gitignore to make sure that it doesn’t end up being tracked in version control.
# Create a .gitignore file
gitignore_content = "data/\n" # Content to exclude the "data" folder
with open('.gitignore', 'w') as gitignore_file:
gitignore_file.write(gitignore_content)I now have the raw data stored locally in the following paths.
data_paths = ["data/" + f for f in files]
data_paths['data/date-hour-soo-dest-2018.csv.gz',
'data/date-hour-soo-dest-2019.csv.gz',
'data/date-hour-soo-dest-2020.csv.gz',
'data/date-hour-soo-dest-2021.csv.gz',
'data/date-hour-soo-dest-2022.csv.gz',
'data/date-hour-soo-dest-2023.csv.gz',
'data/date-hour-soo-dest-2024.csv.gz']Storage with parquet
Since these are in a usable form now, I decided against implementing any other processing steps to the data and preserve a raw form in storage, but I’ll proceed to batch convert this directory and set of files into a directory of parquet files for more efficient data I/O.
When we convert to parquet we’ll get two core benefits:
- The files will be smaller (see Figure 3 ).
- The files can be read into memory much faster.
To do the batch transfer from .csv.gz into parquet, I’ll lazily read in the full directory of .csv.gz files using dask:
Note that what I downloaded above is not all of the BART data I have – just what is currently on the website. I’ve previously downloaded extracts going back to 2011:
all_csv_paths = ["data/" + f for f in os.listdir("data") if f.endswith(".gz")]
all_csv_paths['data/date-hour-soo-dest-2011.csv.gz',
'data/date-hour-soo-dest-2012.csv.gz',
'data/date-hour-soo-dest-2013.csv.gz',
'data/date-hour-soo-dest-2014.csv.gz',
'data/date-hour-soo-dest-2015.csv.gz',
'data/date-hour-soo-dest-2016.csv.gz',
'data/date-hour-soo-dest-2017.csv.gz',
'data/date-hour-soo-dest-2018.csv.gz',
'data/date-hour-soo-dest-2019.csv.gz',
'data/date-hour-soo-dest-2020.csv.gz',
'data/date-hour-soo-dest-2021.csv.gz',
'data/date-hour-soo-dest-2022.csv.gz',
'data/date-hour-soo-dest-2023.csv.gz',
'data/date-hour-soo-dest-2024.csv.gz']data = dd.read_csv(all_csv_paths, blocksize=None, compression='gzip')
data.columns = ['Date', 'Hour', 'Start', 'End', 'Riders']
dataDask DataFrame Structure:
| Date | Hour | Start | End | Riders | |
|---|---|---|---|---|---|
| npartitions=14 | |||||
| string | int64 | string | string | int64 | |
| ... | ... | ... | ... | ... | |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | |
| ... | ... | ... | ... | ... |
Dask Name: operation, 2 expressions
…
Now I’ll establish a subdirectory in data that’s just for the parquet directory
if not os.path.exists('data/parquet_data'):
os.makedirs('data/parquet_data')and I’ll write out to that folder using dask, with a progress bar to monitor how long this takes (note that these progress bars may not be visible in this document).
pbar = ProgressBar()
pbar.register()For data of this size, the one-time conversion typically takes under two minutes
data.to_parquet('data/parquet_data', write_index=False)Storage Comparison
Now that we have the files saved, we can conduct a quick check on how storage size differs. I’ll write a helper function to calculate the total bytes of all the files in a given directory.
def get_local_bytes(directory: str) -> int:
contents: list[str] = os.listdir(directory)
contents_w_path: list[str] = [os.path.join(directory, f) for f in contents]
files_not_folders: list[str] = [f for f in contents_w_path
if os.path.isfile(f)]
return sum(os.path.getsize(f) for f in files_not_folders)Code
fig, ax = plt.subplots()
pd.DataFrame(
{
'.csv.gz': [round(get_local_bytes('data')*10e-7, 2)],
'parquet': [round(get_local_bytes('data/parquet_data')*10e-7, 2)]
}, index=['Bart Data Size']
).T.plot.bar(ax=ax)
ax.bar_label(ax.containers[0], fmt="%g megabytes")
ax.set(ylabel='Megabytes', xlabel='File Type')
ax.tick_params(axis='x', rotation=0)
fig.tight_layout()
fig.savefig('fig1.png', dpi=300)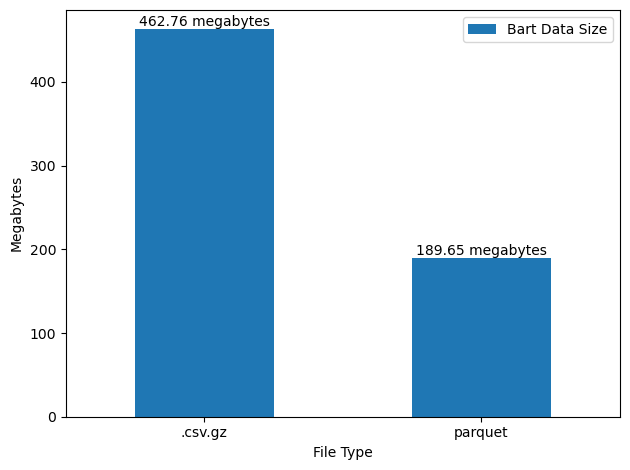
parquet is pretty good here.
Reading parquet
With the data in parquet, it’s now very easy to read in and analyze all of this ridership data, and we’ll see that it’s much faster that working with .csv.gz data (see Figure 4 for the efficiency conclusions).
dask with parquet
Here I’ll use dask to read in about 52 million rows of data in well under 30 seconds, in a single line of code.
Note that the code for reading in the data, dd.read_parquet('data/parquet_data') executes lazily – it’s not reading data into memory yet! I’ve seen some guides online that benchmark dask and pandas based on un-computed dask commands, which completely misses how dask works. Here, I’m going to explicitly call the compute() method at the end of the code, which prompts the actual reading in of the data from local file to memory.
start = time.time()
df = dd.read_parquet('data/parquet_data').compute()
dask_parquet_end = time.time() - startNote that I called start = time.time() and dask_parquet_endtime = time.time() to store the time that it takes to complete this task.
Anyways, we just loaded in fairly large data:
df.shape(122851920, 5)In what seems like a short amount of time:
print(round(dask_parquet_end, 2), "seconds")31.32 secondsand this data is now all in memory as a pandas dataframe, ready for typical use.
df.head()| Date | Hour | Start | End | Riders | |
|---|---|---|---|---|---|
| 0 | 2011-01-01 | 0 | 12TH | 16TH | 1 |
| 1 | 2011-01-01 | 0 | 12TH | 24TH | 3 |
| 2 | 2011-01-01 | 0 | 12TH | ASHB | 2 |
| 3 | 2011-01-01 | 0 | 12TH | BAYF | 5 |
| 4 | 2011-01-01 | 0 | 12TH | CIVC | 3 |
Benchmarking the read-in task
Before we celebrate too much, lets compare that performance to our other possible cases. We’ll compare how the following read-in setups compare:
dask+ parquetdask+.csv.gzpandas+ parquetpandas+.csv.gz
Before I start doing these benchmarks, I’ll need to do some memory cleaning so that I can repeatedly read these files in:
del df
gc.collect()dask with .csv.gz
Here we simply use the .csv.gz files with dask – does the parallel processing in dask make the conversion from .csv.gz to parquet not worth it?
if not os.path.exists("times.csv"):
start = time.time()
df_dask_csv = dd.read_csv(data_paths,
blocksize=None,
compression='gzip').compute()
dask_csv_end = time.time() - start
del df_dask_csv
gc.collect()pandas with .csv.gz
Here we simply use the .csv.gz files with pandas for read-in – how do things look if we use no new libraries and do no file conversions?
if not os.path.exists("times.csv"):
dfs = []
start = time.time()
for csv_path in tqdm(data_paths):
dfs.append(pd.read_csv(csv_path))
df_pandas = pd.concat(dfs)
pandas_csv_end = time.time() - start
del df_pandas
gc.collect()pandas with parquet
Finally, we’ll take advantage of the fact that pandas also supports the read-in of directories of parquet data and try the parquet files with pandas for read-in – can we avoid using dask?
if not os.path.exists("times.csv"):
start = time.time()
df_pandas_parquet = pd.read_parquet('data/parquet_data')
pandas_parquet_end = time.time() - start
del df_pandas_parquet
gc.collect()We’ll answer all of those questions at once with a plot:
Code
if not os.path.exists("times.csv"):
times = pd.DataFrame(
{
'dask + parquet': [round(dask_parquet_end, 2)],
'dask + .csv.gz': [round(dask_csv_end, 2)],
'pandas + parquet': [round(pandas_parquet_end, 2)],
'pandas + .csv.gz': [round(pandas_csv_end, 2)],
}, index=['Bart Data Read-In Time']
)
times.to_csv('times.csv')
else:
times = pd.read_csv('times.csv', index_col=0)
fig, ax = plt.subplots()
times.T.sort_values(by='Bart Data Read-In Time', ascending=False).plot.barh(ax=ax)
ax.bar_label(ax.containers[0], fmt=" %g seconds")
ax.set(xlabel='Seconds', ylabel='Package + Storage Method', xlim=(0, 85))
ax.tick_params(axis='x', rotation=0)
fig.tight_layout()
fig.savefig('fig2.png', dpi=300)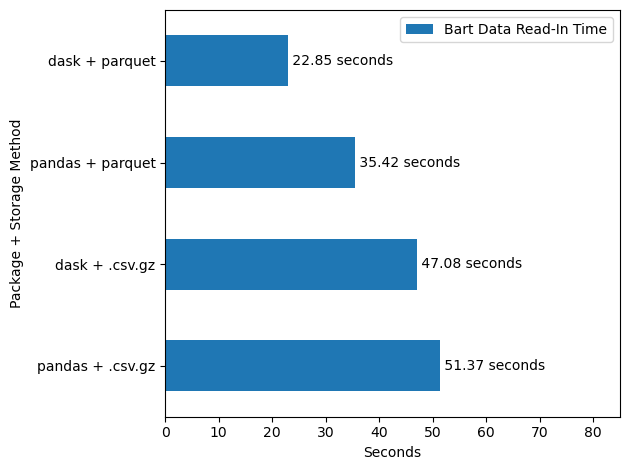
Again, parquet, and especially parquet with dask, looks pretty good here.
Some reflection
These differences in seconds aren’t so massive in the context of this 52 million row dataset. Indeed, in my experience with smaller row counts, just using .csv.gz/.csv with pandas is faster, as dask has to take time to set up parallel jobs at the start, and a parquet conversion has a fixed time cost up front. However, as the size of the data increases, one would expect the gap between the dask + parquet approach to start to diverge from the others more, and the efficiency gains become more important.
Even beyond the time differences, I’m especially partial to dask+parquet due to the difference in how much code is required at read-in. I also love the fact that dask can read in an entire directory of data easily in one line of code:
df = dd.read_parquet('data/parquet_data').compute()Citation
BibTeX citation:
@online{amerkhanian2024,
author = {Amerkhanian, Peter},
title = {Benchmarking Parquet and `Dask`},
date = {2024-04-12},
url = {https://peter-amerkhanian.com/posts/dask-data-io/},
langid = {en}
}
For attribution, please cite this work as:
Amerkhanian, Peter. 2024. “Benchmarking Parquet and
`Dask`.” April 12, 2024. https://peter-amerkhanian.com/posts/dask-data-io/.