Using re-sampling to better estimate model performance.
Python
Statistics
Author
Peter Amerkhanian
Published
December 8, 2023
Code
import numpy as npimport pandas as pdpd.set_option("display.float_format", "{:.2f}".format)import matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_squared_error, r2_scorefrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.tree import DecisionTreeRegressordef model_data_lm(degree, df): X = df[["Education"]].values y = df["Income"].values model = make_pipeline(PolynomialFeatures(degree), LinearRegression()) model.fit(X, y) rmse = mean_squared_error(y, model.predict(X)) **0.5 r2 = r2_score(y, model.predict(X)) X_test = np.linspace(X.min() -1.5* X.std(), X.max() +1.5* X.std(), 100).reshape(-1, 1 ) y_pred = model.predict(X_test)return X_test, y_pred, rmse, r2, model
Some Notes on Modeling Data and Resampling Methods
The following is an exercise with synthetic data intended to memorialize some thoughts on models and resampling methods. I won’t reference a lot of specific books here, but generally this post is influenced by James et al. (2013) and Hastie, Tibshirani, and Friedman (2016).
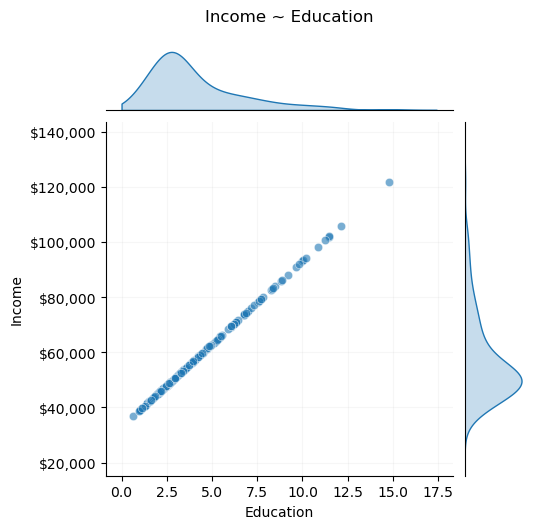
To begin, say we are examining the relationship between income and years of education.
The relationship is governed by the deterministic function, which is a data generating process (DGP): \[
income = 33000 + 6000 \times education
\]
Code
g = sns.JointGrid(data=df, x="Education", y="Income", marginal_ticks=False, height=5)g.plot_joint(sns.scatterplot, alpha=0.6, marker="o")g.plot_marginals(sns.kdeplot, fill=True, clip=(0, np.inf))g.fig.suptitle(f"Income ~ Education", y=1.05)g.ax_joint.grid(alpha=0.1)# Formatting the sidesg.ax_joint.yaxis.set_major_formatter("${x:,.0f}")g.ax_marg_x.tick_params(left=False, bottom=False)g.ax_marg_y.tick_params(left=False, bottom=False)g.ax_marg_y.set(xticklabels=[]);
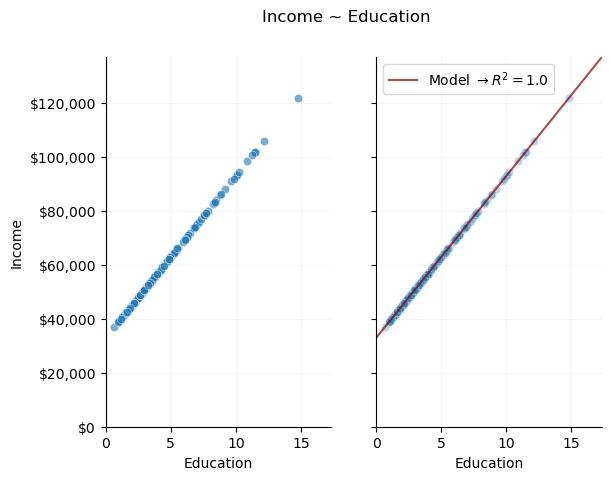
Modeling this relationship is trivial. Given that it is a deterministic, linear function, we can use data to solve a linear system of equations and find the exact parameters of the relationship:
\(R^2\) is the percentage of variance in the outcome, income, that our model can describe (in this case 100%, a perfect fit). We’ve created a perfect model of the DGP.
Modeling a Non-Deterministic Process
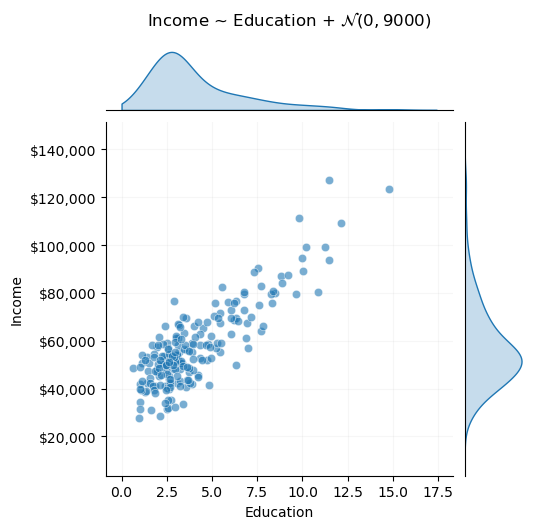
In policy analysis settings, it’s rare that we would encounter deterministic processes that we have any interest in modeling. Instead, we typically encounter processes with some stochastic element. For example, the following is a new DGP, where income is a linear function of years of education, but with an added random variable, representing noise.
noise_std =9000DGP =lambda x: 33000+6000* x + np.random.normal(0, noise_std, size=len(x))
Modeling this process is no longer trivial. Rather than solve a simple system of equations algebraically, we must use an estimation method to find a “best” model. Estimation involves choices, and finding the best model for this data is more complex than it may seem at first glance.
Overfitting
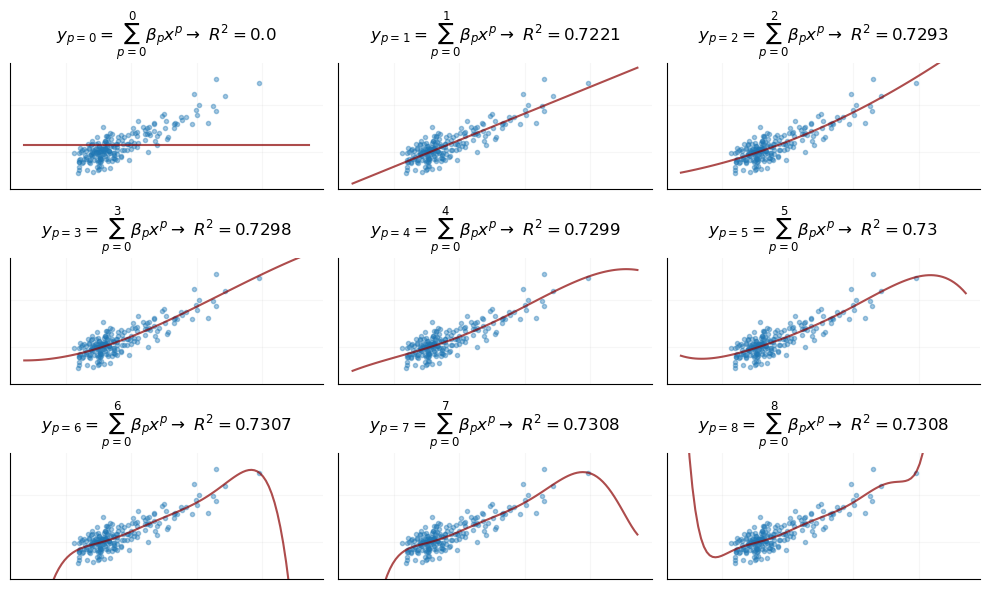
We will model this DGP using a linear regression fit via the ordinary least squares algorithm. We face a number of choices in using linear regression – for example, we can freely use polynomial transformations to make our model flexible to non-linear relationships. Here we’ll examine the behavior of a polynomial regression by setting up an infinite series as follows: \[
y_p=\sum_{p=0}^{\infty} \beta_p x^p
\] As this series expands, it represents a polynomial regression of degree \(p\). When we expand, we can examine how this model performs as the degree increases.
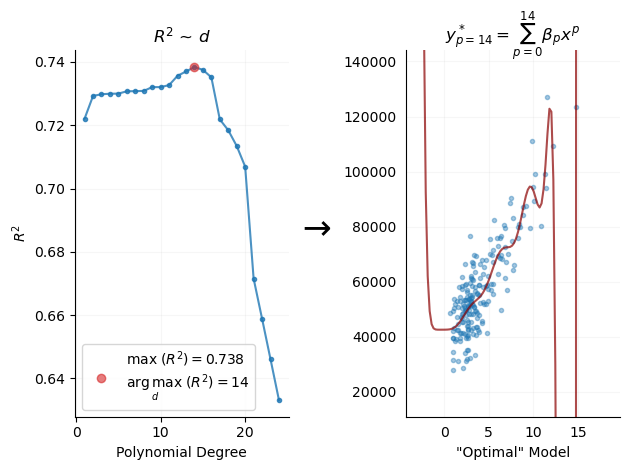
Regardless of what you think of the shape of these curves, it’s clear that as the series expands and \(p\) increases, we see improving model accuracy, \(R^2\). We can expand this series until we find a seemingly “optimal” model.
An “Optimal” Model
We expand the series, or, in more typical language, we conduct a “grid-search,” to find the optimal model as defined by the maximum \(R^2\) score:
We see that the accuracy-maximizing model, \(y^*\), is a very high degree polynomial. Our simple, empirical investigation leads us to conclude that this is the “best” model.
However, it’s clear that the model is overly complex and likely problematic given these visuals, where there are extreme swings in predictions. It would greatly benefit us to have a clear quantity that represents why this model may be problematic.
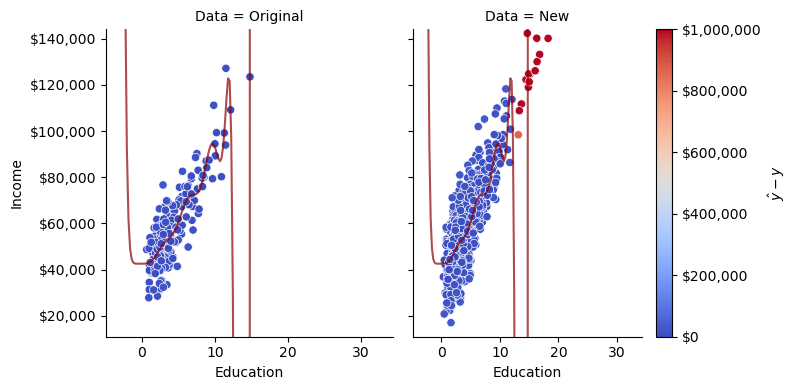
Out of sample performance, or, what happens when we collect new data?
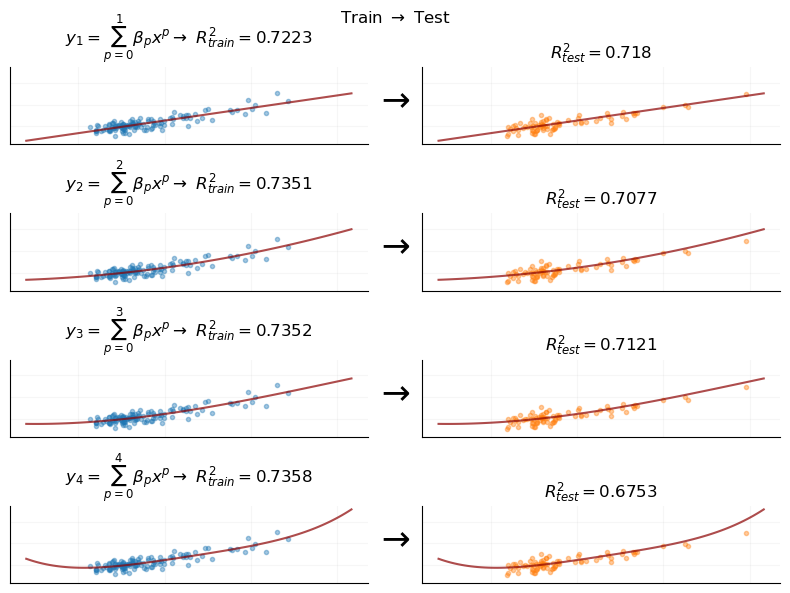
One simple way to further evaluate this model is to collect new data (from outside of our original sample) and then evaluate whether the model can describe variation in that new data. Given that we are working with synthetic data, it’s straightforward to simulate new observations from the underlying DGP, and thus “collect” new data. In the following plot, the right-hand pane is a fresh sample of individuals with observed education and income values:
This is clearly a bad model. What’s worrying is that it seemed like the best model when we simply examined model accuracy on one dataset. This raises the possibility that we might be duped into selecting models like this in practice.
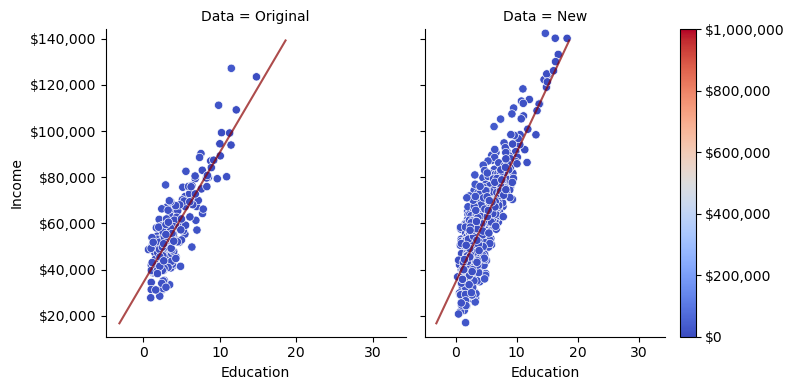
Out of curiosity, let’s see how an extremely simply model, a linear regression with \(p=1\) compares on this new data.
We have the benefit of already knowing that \(p=1\) matches the functional form of the true DGP, but even if we didn’t know that in advance, out-of-sample performance seems like a better way of evaluating whether or not our model gets at the underlying DGP of the observations.
The Train-Test Split
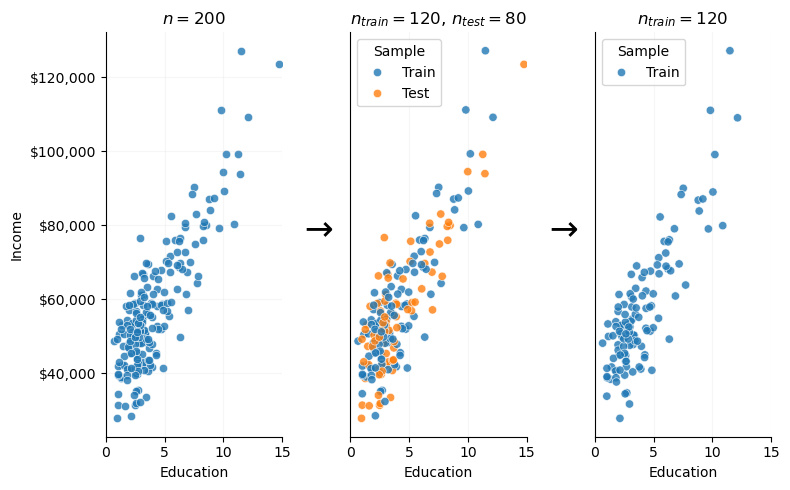
The process we just went through is analogous to a resampling method called the train-test split.
In the real world, we rarely can just collect more data. However, it is straightforward to simulate the data collection process using resampling methods. Specifically, we can split our original dataset into two parts – a training dataset, wherein we will train and intially evaluate our model, and a “test” dataset, which we will use just as we used the newly collected data in the previous example, for more objective, empirical model evaluation.
We proceed to train models on the training data, and evaluate each model on the test dataset. We do that process for each degree polynomial regression.
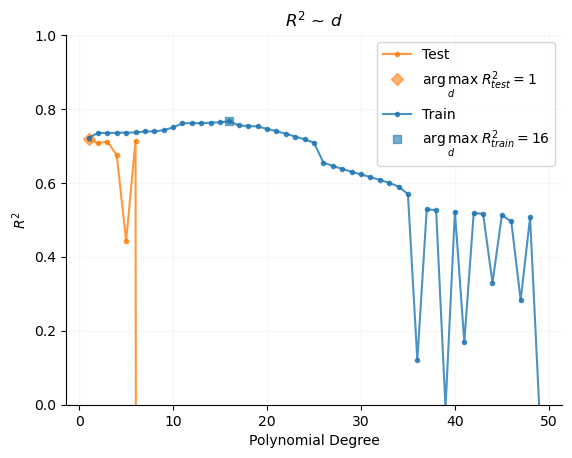
When we examine the relationship between polynomial degree and \(R^2\), we now seek the argument that maximizes \(R^2_{test}\), rather than \(R^2_{train}\).
Here we’ll also note that, typically, \(R^2_{test} < R^2_{train}\).
Here we see the benefit of the train-test split. Were we using only a training dataset, we may naively optimize our model at \(p=16\). However, by using a test dataset for model evaluation, our empirically optimized model is at \(p=1\), thus matching the true functional form of the underlying data generating process, a linear function of the form:
\[
income = 33000 + 6000 \times education + \mathcal{N}(0, 9000)
\] Indeed, we can see the exact functional form that our optimal model takes:
income = 34467.82 + 5635.04*education + N(-90.57, 9138.91)
This is very close to the data generating process!
An Aside about Nonparametric models
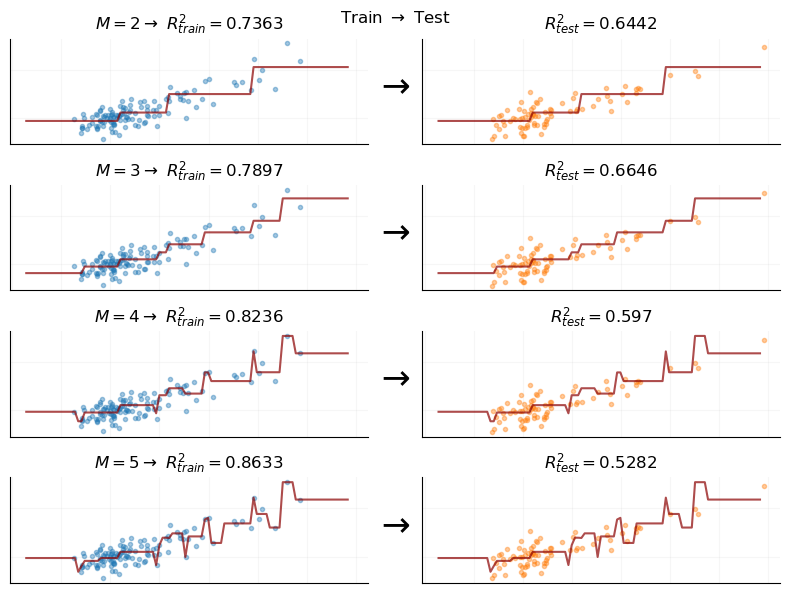
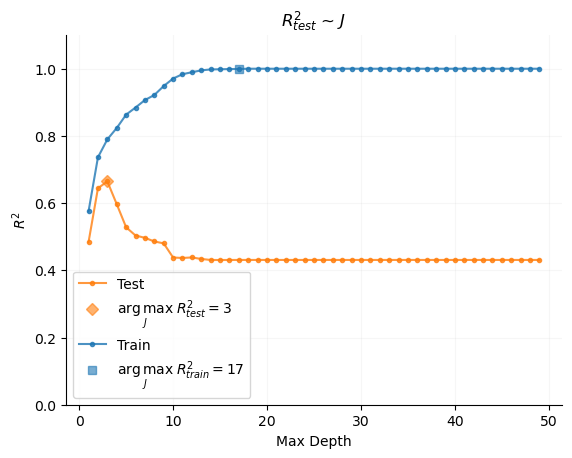
The issues we just discussed in the context of polynomial regression only compound as we exit the realm of linear regression and consider nonparametric models like decision trees. For example, when we examine a decision tree model and vary \(M\), the number of partitions of the feature space that the model uses (a measure of complexity), we see extreme divergence between training the testing performance.
Indeed, it even seems visually that, at some level, \[
\lim_{M \rightarrow \infty} R_{train}^2 \approx 1.0
\] Being able to perfectly model a DGP that is in itself random is a worrying sign, and this condition creates especial danger of over-fitting and creating overly-confident models when using decision trees.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2016. The Elements of StatisticalLearning: DataMining, Inference, and Prediction, SecondEdition. 2nd edition. New York, NY: Springer.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An Introduction to StatisticalLearning: With Applications in R. 1st ed. 2013, Corr. 7th printing 2017 edition. New York Heidelberg Dordrecht London: Springer.
Citation
BibTeX citation:
@online{amerkhanian2023,
author = {Amerkhanian, Peter},
title = {Overfitting and {The} {Train-Test} {Split}},
date = {2023-12-08},
url = {https://peter-amerkhanian.com/posts/overfitting/},
langid = {en}
}